最近,NetEase Fuxi实验室将强化学习引入了游戏AI开发的新成就,“应用强化学习来开发NetEase游戏中的游戏AI”,成功地为游戏开发人员会议(GDC)2020 Core选择了!

该提案是独立开发和独立交付NetEase Fuxi实验室的结果。这是第一个接管GDC核心的国内游戏研发计划,并反映了NetEases Fuxi实验室的一流游戏AI开发能力。
在进步和撤退之间:AI开发游戏的瓶颈
那么,从世界顶级游戏开发人员活动中获得了什么样的技术和应用程序结果?今天,本文将从游戏AI的当前发展状态开始,并详细说明Fuxi实验室在增强学习游戏AI商业化中的最新探索和突破。
在实际情况下,人工智能在商业实施方面还有很长的路要走,并且在人类世界中面临许多复杂问题的算法系统从未达到足够的数量级。
虽然,世界一流的顶级公司基于两款游戏开发了AI AI -DeepMind和Openai,Starcraft 2(Starcraft 2)和Dota 2 -DeepMind和Openai达到了顶级人类球员的水平。但是,作为科学研究领域的尖端探索,这两个AI更像是使用游戏的完美训练环境进行人工智能研究,投资庞大的培训资源;花费大量培训时间;并在面对人类时增加许多限制。
换句话说,现有的游戏AI并不完全适合商业游戏中面向用户的内容开发,而国际顶级游戏AI级别不能成为商业标准。
DeepMind Starcraft AI降落在自然上
应该很明显的是,商业游戏AI的实施和开发应具有较高的投入输出比。同时,为了给玩家提供更好的游戏体验,AI的获胜率不是唯一的评估标准,但更重要的是,它可以为AI提供各种行为,智慧和有趣的行为。对于这些考虑因素,商业游戏AI开发领域仍处于安静的时期。
获胜工具:加强学习有助于游戏AI破冰旅程
作为R&D NetEase Games的研发部,NetEase Fuxi实验室近年来一直在AI领域不断努力。它在MOBA,MMORPG,SPG等游戏类型的商业游戏转型方面积累了丰富的经验,为业务和技术提供了综合而有力的保证。
这种AI增强功能得到了实验室的深层人工智能背景的支持,并使用诸如增强型学习之类的子部门专注于Game AI在NetEase Games练习中的特定应用。下面我们将主要介绍AI开发过程中遇到的问题,解决方案尝试和最终结果。
最初,基于Netase Games的AI开发需求,Fuxi实验室发现,与传统的AI方法(有限状态机器,行为树)相比,学习AI具有其独特的优势,主要反映在AI行为的理性,复杂性和多样性中。
在“反对寒冷”类型的比赛场景中,AI的最高困难不仅超过了技术领域的最高球员,而且其合理的比赛风格也得到了游戏制作团队的高度认可。
AI完全限制了球员,以“反对冷”的类型竞争为例
在时尚篮球的3V3场景中,游戏AI不仅学习了基本的突破,通过和射击,而且还学会了许多高级合作 - 挑选,助攻,辅助防守和中断得分。

时尚篮球3V3人与机器战斗
当然,这项新技术也有一定的局限性,初始访问成本高,迭代较长的迭代周期和无法控制的培训效果。为了克服这些困难,实验室进一步开发了一套培训工具,主体包括前端流程图和后端自我开发算法框架,总结了一系列解决方案,并构成了一套完整的开发过程规格,从而极大地提高了开发效率。
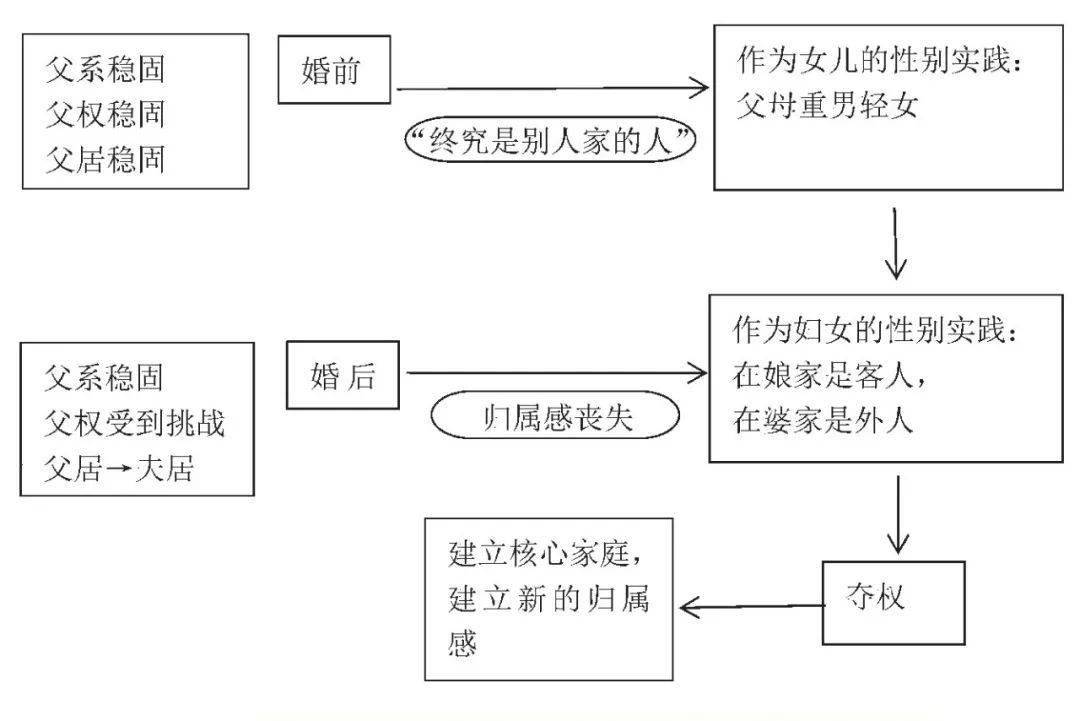
前端流程图
上图是NetEase实际游戏中的前端流程图。除了定义一些基本行为外,该流程图还在某些关键情况下引入了强化学习。图片中的扩大区域是两个与加固学习有关的节点 - SendState和SendReward。该工具简化了游戏访问过程,采用了视觉编程解决方案并提供在线调试功能。该工具支持逻辑规则和强化学习的混合编程,并可以灵活地响应复杂的方案需求。
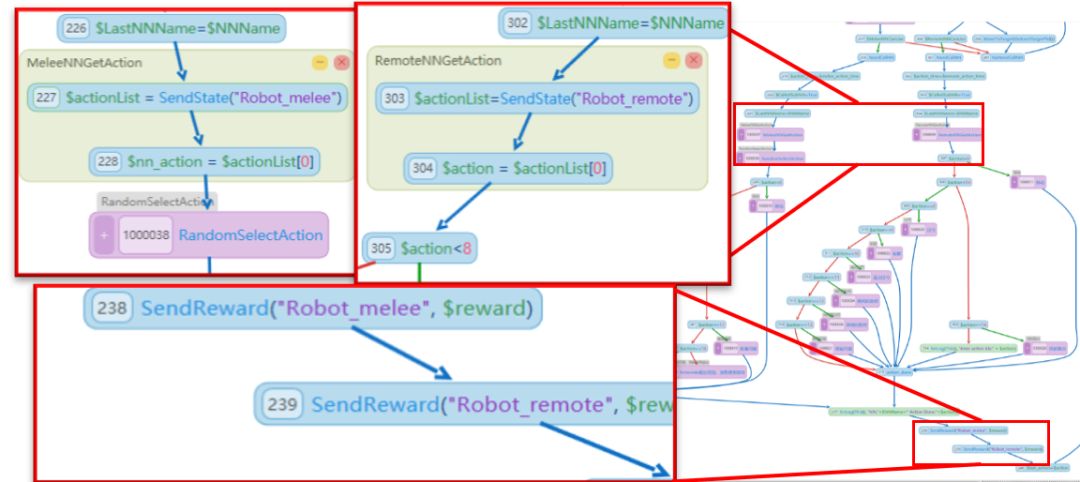
Rlease的框架图
后端算法框架Roles对游戏AI方案进行了许多优化。它不仅支持各种主流算法和游戏类型,而且还具有用于强化学习算法特征的标准API接口,提供了分层的增强学习和支持高级功能,例如分布式培训,自我播放,多样化的样式和难以控制。对于使用流程图工具的游戏,您可以快速访问REALE培训。
网络游戏中实际问题的几种解决方案
在AI开发过程中,培训资源需求很大,限制性,访问成本很高,迭代周期很长,训练效果是无法控制的。该实验室根据实际游戏操作中的产品需求提供技术支持,提供多种解决方案并在特定的游戏方案中获得初步应用程序。
以下是一些部分升级以说明:
1。减少培训资源要求以降低游戏AI生产成本并增加输入输出比。
使用更灵活的建模解决方案进行创建生物或多代理方案,以减少由于图像输入而对硬件资源的高需求。一个与众不同的例子是龙的剑专业在“反对冷”中的Qi剑技能,在AI开发中使用雷达状态表示,并使用向量来表示数字不确定的Qi剑的信息和不确定的位置,从而避免在训练过程中引入卷积层并减少对GPU的需求。
2。在大型场景中减少培训的困难,并巧妙地使用课程学习方法。
在实际的游戏场景中,在大地图上移动比战斗更难训练。这一发展采用了一种逐步的课程学习方法,使AI可以开始进行近距离战斗的训练,并随着培训的进行而缓慢距离双方,最终使AI学习了更高级别的策略 - 跟踪,逃脱等。
3。全面匹配各个级别的玩家,以改善游戏体验。
使用多个行为参数来控制各种难度的AI的产生,并使用Trueskill或ELO技术建立统一的评估系统。与不同级别的玩家相匹配的AI是游戏中的基本要求。为了控制和评估AI难度,实验室引入了参数控制机制(如下图所示),并使用ELO一次产生了与各种参数相对应的不同难度的AI,这不仅降低了计划和选择AI的过程,而且还提供了客观的难度评估标准。

难度控制迭代图
4。使AI更像人类,并促进AI的风格化。
真正的玩家经常在许多方面打球。为了与各种风格的对手打交道,人工智能必须使训练对手更加多样化。实验室使用多种种子和多个奖励参数的混合培训,并同时生成具有多种行为样式的AI。尽管使用自我游戏训练方法可以在一定程度上产生具有行为多样性的AI,但仍然很容易陷入整个本地行为。为了克服这个问题,后端算法框架引入了各种奖励参数,以同时训练。
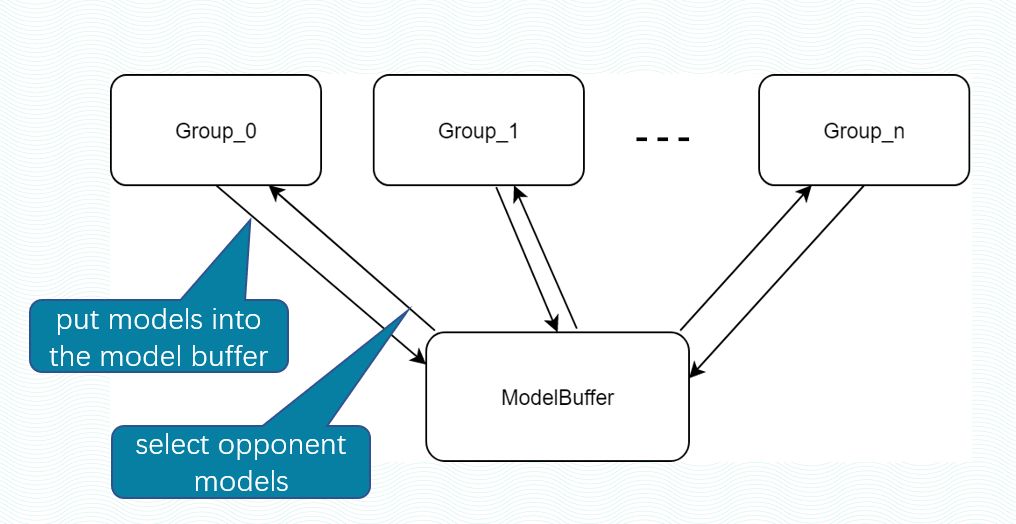
多式混合训练图

不同的奖励参数意味着AI具有不同的目标(尤其是激进的,保守的等),并且主要培训代理将在训练过程中遇到这些不同的目标并努力击败它们,从而降低AI在推出后无法适应多样的玩家的比赛风格的风险。
5。使用分层的增强学习技术来简化建模并提高复杂场景中的训练效率。
在“时尚人物篮球”的实际发展中,很难以高级行为训练AI,需要大量的培训和细致的奖励和惩罚设计。为了解决这个问题,团队最终采用了一种分层的强化学习方法,使高级网络可以决定宏观策略(例如防御或挑选式巡回赛),而下层网络则在高层网络的指导下学习特定的操作,从而大大减少了培训的困难。
结果和前景
目前,Fuxi实验室开发的加强学习AI为各种游戏提供了在线服务,包括“反对冷”,“中国幽灵故事手机游戏”,“流星蝴蝶剑”和“时尚的人篮球”。
根据项目团队的数据,仅在“反对冷”类型的比赛游戏中,AI服务的高峰访问达到每秒8,000多,平均每日请求量超过7,000万。此外,在评估过程中学习AI的行为多样性和最高难度超过了原始行为树AI,这是对原始游戏AI的巨大升级。

“对抗寒冷”
此外,根据强化学习AI的推出后,基于用户数据调查,社区对游戏AI升级的讨论仍然很受欢迎。 “我认为我正在与真实的人作斗争”和“我无法击败那些水平的人”已成为大多数球员的共识。它还报道说,新版本的AI不仅在使用组合技能方面是合理且平稳的,而且更像是真正玩家会选择的操作。甚至建议新手玩家学习AI游戏。可以说,“反对寒冷”的流派竞争不仅是对NetEase内部AI的巨大升级,而且是中国罕见的超级AI实用场景。

对“反对冷”用户社区的真实评估
同时,AI天花板大大增加了,这为游戏计划提供了技术支持,以进一步丰富游戏中的游戏玩法。在特定应用方面,已经在流派比赛中添加了两种新的游戏方法,加强了武术和武术训练,为不同玩家提供了更合适的匹配模式,从而大大提高了游戏的可玩性。一见钟情比听到它更好。如何处理游戏AI并主导人类玩家?请看特定视频。
真正的球员与游戏AI战斗的记录过程
可以说,NetEase Fuxi实验室的AI游戏最近进展为该行业提供了一种新的方式来制作商业游戏AI,一套完整的新工具与开发合作以及一套完整的开发规格。与传统方法相比,它不仅提供了更高质量的游戏AI功能,还简化了访问新技术的阈值,而且还解决了一系列常见的问题,在迭代中学习AI。它基于三个入口处的商业用途,以确保商业用途并帮助大规模的商业用途。
我们认为,通过增强AI探索环境的能力以及现有模型的机器学习算法的持续更新和迭代,未来的游戏玩法将经历巨大的变化,并且玩家将能够获得与现实生活中无限接近的游戏体验,以便在游戏内容本身中更加沉浸在现实生活中。也许在美国戏剧“ Westworld”中的游戏概念对每个人来说都是错误的。
将来,NetEase Fuxi实验室将继续加深其在AI领域的努力,扩展其技术能力,为更多游戏提供AI支持,并帮助行业发展。请等待看看!

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请联系本站,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.sudachem.com/html/tiyuwenda/9681.html